Exponential family of probability distributions
 From Encyclopedia of Mathematics - Reading time: 6 min
From Encyclopedia of Mathematics - Reading time: 6 min
A certain model (i.e., a set of probability distributions on the same measurable space) in statistics which is widely used and studied for two reasons:
i) many classical models are actually exponential families;
ii) most of the classical methods of estimation of parameters and testing work successfully when the model is an exponential family.
The definitions found in the literature can be rather inelegant or lacking rigour. A mathematically satisfactory definition is obtained by first defining a significant particular case, namely the natural exponential family, and then using it to define general exponential families.
Given a finite-dimensional real linear space $E$, denote by $E ^ { * }$ the space of linear forms $\theta$ from $E$ to $\mathbf{R}$. One writes $\langle \theta , x \rangle $ instead of $\theta ( x )$. Let $\mu$ be a positive measure on $E$ (equipped with Borel sets), and assume that $\mu$ is not concentrated on an affine hyperplane of $E$. Denote by
\begin{equation*} L _ { \mu } ( \theta ) = \int _ { E } \operatorname { exp } \langle \theta , x \rangle \mu ( d x ) \end{equation*}
its Laplace transform and by $D ( \mu )$ the subset of $E ^ { * }$ on which $L _ { \mu } ( \theta )$ is finite. It is easily seen that $D ( \mu )$ is convex. Assume that the interior $\Theta ( \mu )$ of $D ( \mu )$ is not empty. The set of probability measures (cf. also Probability measure) on $E$:
\begin{equation*} F = F ( \mu ) = \{ \mathsf{P} ( \theta , \mu ) : \theta \in \Theta ( \mu ) \}, \end{equation*}
where
\begin{equation*} \mathsf{P} ( \theta , \mu ) ( d x ) = \frac { 1 } { L _ { \mu } ( \theta ) } \operatorname { exp } \langle \theta , x \rangle \mu ( d x ), \end{equation*}
is called the natural exponential family (abbreviated NEF) generated by $\mu$. The mapping
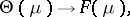 |
\begin{equation*} \theta \mapsto \mathsf{P} ( \theta , \mu ), \end{equation*}
is called the canonical parametrization of $F ( \mu )$. A simple example of a natural exponential family is given by the family of binomial distributions $B ( n , p )$, $0 < p < 1$, with fixed parameter $n$, generated by the measure
\begin{equation*} \mu ( d x ) = \sum _ { k = 0 } ^ { n } \left( \begin{array} { l } { n } \\ { k } \end{array} \right) \delta _ { k } ( d x ), \end{equation*}
where $\delta _ { k }$ is the Dirac measure (cf. Measure) on $k$ (cf. also Binomial distribution). Here, with $p = e ^ { \theta } / ( 1 + e ^ { \theta } )$ and $q = 1 - p$ one has
\begin{equation*} \mathsf{P} ( \theta , \mu ) ( d x ) = \sum _ { k = 0 } ^ { n } \left( \begin{array} { l } { n } \\ { k } \end{array} \right) p ^ { k } q ^ { n - k } \delta _ { k } ( d x ). \end{equation*}
Note that the canonical parametrization by $\theta$ generally differs from a more familiar parametrization if the natural exponential family is a classical family. This is illustrated by the above example, where the parametrization by $p$ is traditional.
A general exponential family (abbreviated GEF) is defined on an abstract measure space $( \Omega , \mathcal{A} , \nu )$ (the measure $\nu$ is not necessarily bounded) by a measurable mapping $t$ from $\Omega$ to a finite-dimensional real linear space $E$. This mapping $t$ must have the following property: the image $\mu$ of $\nu$ by $t$ must be such that $\mu$ is not concentrated on an affine hyperplane of $E$, and such that $\Theta ( \mu )$ is not empty. Under these circumstances, the general exponential family on $\Omega$ generated by $( t , \nu )$ is:
\begin{equation*} F ( t , \nu ) = \{ \mathsf{P} ( \theta , t , \nu ) : \theta \in \Theta ( \mu ) \}, \end{equation*}
where
\begin{equation*} \mathsf{P} ( \theta , t , \nu ) ( d \omega ) = \frac { 1 } { L _ { \mu } ( \theta ) } \operatorname { exp } \langle \theta , t ( \omega ) \rangle \nu ( d \omega ). \end{equation*}
In this case, the NEF $F ( \mu )$ on $E$ is said to be associated to the GEF $F ( t , \nu )$. In a sense, all results about GEFs are actually results about their associated NEF. The dimension of $E$ is called the order of the general exponential family.
The most celebrated example of a general exponential family is the family of the normal distributions $N ( m , \sigma ^ { 2 } )$ on $\Omega = \mathbf{R}$, where the mean $m$ and the variance $\sigma ^ { 2 }$ are both unknown parameters (cf. also Normal distribution). Here, $\nu ( d \omega ) = d x / \sqrt { 2 \pi }$, the space $E$ is $\mathbf{R} ^ { 2 }$ and $t ( \omega )$ is $( \omega , \omega ^ { 2 } / 2 )$. Here, again, the canonical parametrization is not the classical one but is related to it by $\theta _ { 1 } = m / \sigma ^ { 2 }$ and $\theta _ { 2 } = - 1 / \sigma ^ { 2 }$. The associated NEF is concentrated on a parabola in $\mathbf{R} ^ { 2 }$.
A common incorrect statement about such a model says that it belongs to "the" exponential family. Such a statement is induced by a confusion between a definite probability distribution and a family of them. When a NEF is concentrated on the set of non-negative integers, its elements are sometimes called "power series" distributions, since the Laplace transform is more conveniently written $L _ { \mu } ( \theta ) = f ( e ^ { \theta } )$, where $f$ is analytic around $0$. The same confusion arises here.
There are several variations of the above definition of a GEF: mostly, the parameter $\theta$ is taken to belong to $D ( \mu )$ and not only to $\Theta ( \mu )$, thus obtaining what one may call a full-NEF. A full-GEF is similarly obtained. However, many results are not true anymore for such an extension: for instance, this is the case for the NEF on $\mathbf{R}$ generated by a positive stable distribution $\mu$ with parameter $1/2$: this NEF is a family of inverse Gaussian distributions, with exponential moments, while $\mu$ has no expectation and belongs to the full-NEF. A more genuine extension gives curved exponential families (abbreviated CEF). In this case, the set of parameters is restricted to a non-affine subset of $\Theta ( \mu )$, generally a manifold. However, this extension is in a sense too general, since most of the models in statistics can be regarded as a CEF. The reason is the following: Starting from a statistical model of the form $F = \{ f d \nu : f \in S \}$, where $S$ is a subset of $L ^ { 1 } ( \nu )$, then $F$ is a CEF if and only if the linear subspace of the space $L ^ { 0 } ( \nu )$ generated by the set $\{ \operatorname { log } f : f \in S \}$ is finite dimensional. This is also why exponential families constructed on infinite-dimensional spaces are uninteresting (at least without further structure). For these CEFs, there are no really general results available concerning the application of the maximum-likelihood method. General references are [a2] and [a5].
The exponential dispersion model (abbreviated, EDP) is a concept which is related to natural exponential families as follows: starting from the NEF $F ( \mu )$ on $E$, the Jorgensen set $\Lambda ( \mu )$ is the set of positive $p$ such that there exists a positive measure $\mu _ { p }$ on $E$ whose Laplace transform is $( L _ { \mu } ) ^ { p }$ (see [a4]. Trivially, it contains all positive integers. The model
\begin{equation*} \{ \mathsf{P} ( \theta , \mu _ { p } ) : \theta \in \Theta ( \mu ) , p \in \Lambda ( \mu ) \} \end{equation*}
is the exponential dispersion model generated by $\mu$. It has the following striking property: Let $\theta$ be fixed in $\Theta ( \mu )$, let $p _ { 1 } , \dots , p _ { n }$ be in $\Lambda ( \mu )$ and let $X _ { 1 } , \ldots , X _ { n }$ be independent random variables with respective distributions $\mathsf{P} ( \theta , \mu _ { p _ { j } } )$, with $j = 1 , \ldots , n$. Then the distribution of $( X _ { 1 } , \ldots , X _ { n } )$ conditioned by $S = X _ { 1 } + \ldots + X _ { n }$ does not depend on $\theta$. The distribution of $S$ is obviously $\mathsf{P} ( \theta , \mu _ { p } )$ with $p = p _ { 1 } + \ldots + p _ { n }$. Furthermore, if the parameters $p _ { 1 } , \dots , p _ { n }$ are known, and if $\theta$ is unknown, then the maximum-likelihood method to estimate $\theta$ from the knowledge of the observations $( X _ { 1 } , \ldots , X _ { n } )$ is the one obtained from the knowledge of $S$. For instance, if the NEF is the Bernoulli family of distributions $q \delta _ { 0 } + p \delta _ { 1 }$ on $0$ and $1$, if $X _ { 1 } , \ldots , X _ { n }$ are independent Bernoulli random variables with the same unknown $p$, then in order to estimate $p$ it is useless to keep track of the individual values of the $X _ { 1 } , \ldots , X _ { n }$. All necessary information about $p$ is contained in $S$, which has a binomial distribution $B ( n , p )$.
Thus, the problem of estimating the canonical parameter $\theta$, given $n$ independent observations $X _ { 1 } , \ldots , X _ { n }$, for a NEF model is reduced to the problem of estimating with only one observation $S$, whose distribution is in the NEF $F ( \mu _ { n } )$. See Natural exponential family of probability distributions for details about estimation by the maximum-likelihood method. When dealing with a GEF, the problem is reduced to the associated NEF.
Bayesian theory (cf. also Bayesian approach) also constitutes a successful domain of application of exponential families. Given a NEF $F ( \mu )$ and a positive measure $\alpha ( d \theta )$ on $\Theta ( \mu )$, consider the set of $( v , p ) \in E \times \mathbf{R}$ such that
\begin{equation*} \pi _ { v , p } ( d \theta ) = A ( m , p ) ( L _ { \mu } ( \theta ) ) ^ { - p } \operatorname { exp } \langle \theta , v \rangle \alpha ( d \theta ) \end{equation*}
is a probability for some number $A ( v , p )$, and assume that this set is not empty. This set of a priori distributions on the parameter space is an example of a conjugate family. This means that if the random variable $( \theta , X )$ has distribution $\pi _ { v , p } ( d \theta ) \mathsf{P} ( \theta , \mu ) ( d x )$, then the distribution of $\theta$ conditioned by $X = x$ (a posteriori distribution) is $\pi _ { v ^ { \prime } , p ^ { \prime } }$ for some $( v ^ { \prime } , p ^ { \prime } )$ depending on $v , p , x$. See [a1] for a complete study; however, [a3] is devoted to the case $\alpha ( d \theta ) = d \theta$, which has special properties and has, for many years, been the only serious study of the subject.
References[edit]
| [a1] | S. Bar-Lev, P. Enis, G. Letac, "Sampling models which admit a given general exponential family as a conjugate family of priors" Ann. Statist. , 22 (1994) pp. 1555–1586 |
| [a2] | O. Barndorff-Nielsen, "Information and exponential families in statistical theory" , Wiley (1978) |
| [a3] | P. Diaconis, D. Ylvizaker, "Conjugate priors for exponential families" Ann. Statist. , 7 (1979) pp. 269–281 |
| [a4] | B. Jorgensen, "Exponential dispersion models" J. R. Statist. Soc. Ser. B , 49 (1987) pp. 127–162 |
| [a5] | G. Letac, "Lectures on natural exponential families and their variance functions" , Monogr. Mat. , 50 , Inst. Mat. Pura Aplic. Rio (1992) |
 EncycloReader
is supported by the
EncycloReader
is supported by the