Table of Contents Categories
Transportation theory (mathematics)
 From HandWiki - Reading time: 13 min
From HandWiki - Reading time: 13 min
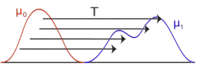
In mathematics and economics, transportation theory or transport theory is a name given to the study of optimal transportation and allocation of resources. The problem was formalized by the French mathematician Gaspard Monge in 1781.[1]
In the 1920s A.N. Tolstoi was one of the first to study the transportation problem mathematically. In 1930, in the collection Transportation Planning Volume I for the National Commissariat of Transportation of the Soviet Union, he published a paper "Methods of Finding the Minimal Kilometrage in Cargo-transportation in space".[2][3]
Major advances were made in the field during World War II by the Soviet mathematician and economist Leonid Kantorovich.[4] Consequently, the problem as it is stated is sometimes known as the Monge–Kantorovich transportation problem.[5] The linear programming formulation of the transportation problem is also known as the Hitchcock–Koopmans transportation problem.[6]
Motivation
Mines and factories
Suppose that we have a collection of m mines mining iron ore, and a collection of n factories which use the iron ore that the mines produce. Suppose for the sake of argument that these mines and factories form two disjoint subsets M and F of the Euclidean plane R2. Suppose also that we have a cost function c : R2 × R2 → [0, ∞), so that c(x, y) is the cost of transporting one shipment of iron from x to y. For simplicity, we ignore the time taken to do the transporting. We also assume that each mine can supply only one factory (no splitting of shipments) and that each factory requires precisely one shipment to be in operation (factories cannot work at half- or double-capacity). Having made the above assumptions, a transport plan is a bijection T : M → F. In other words, each mine m ∈ M supplies precisely one target factory T(m) ∈ F and each factory is supplied by precisely one mine. We wish to find the optimal transport plan, the plan T whose total cost
is the least of all possible transport plans from M to F. This motivating special case of the transportation problem is an instance of the assignment problem. More specifically, it is equivalent to finding a minimum weight matching in a bipartite graph.
Moving books: the importance of the cost function
The following simple example illustrates the importance of the cost function in determining the optimal transport plan. Suppose that we have n books of equal width on a shelf (the real line), arranged in a single contiguous block. We wish to rearrange them into another contiguous block, but shifted one book-width to the right. Two obvious candidates for the optimal transport plan present themselves:
- move all n books one book-width to the right ("many small moves");
- move the left-most book n book-widths to the right and leave all other books fixed ("one big move").
If the cost function is proportional to Euclidean distance (c(x, y) = α|x − y|) then these two candidates are both optimal. If, on the other hand, we choose the strictly convex cost function proportional to the square of Euclidean distance (c(x, y) = α|x − y|2), then the "many small moves" option becomes the unique minimizer.
Note that the above cost functions consider only the horizontal distance traveled by the books, not the horizontal distance traveled by a device used to pick each book up and move the book into position. If the latter is considered instead, then, of the two transport plans, the second is always optimal for the Euclidean distance, while, provided there are at least 3 books, the first transport plan is optimal for the squared Euclidean distance.
Hitchcock problem
The following transportation problem formulation is credited to F. L. Hitchcock:[7]
- Suppose there are m sources for a commodity, with units of supply at xi and n sinks for the commodity, with the demand at yj. If is the unit cost of shipment from xi to yj, find a flow that satisfies demand from supplies and minimizes the flow cost. This challenge in logistics was taken up by D. R. Fulkerson[8] and in the book Flows in Networks (1962) written with L. R. Ford Jr.[9]
Tjalling Koopmans is also credited with formulations of transport economics and allocation of resources.
Abstract formulation of the problem
Monge and Kantorovich formulations
The transportation problem as it is stated in modern or more technical literature looks somewhat different because of the development of Riemannian geometry and measure theory. The mines-factories example, simple as it is, is a useful reference point when thinking of the abstract case. In this setting, we allow the possibility that we may not wish to keep all mines and factories open for business, and allow mines to supply more than one factory, and factories to accept iron from more than one mine.
Let and be two separable metric spaces such that any probability measure on (or ) is a Radon measure (i.e. they are Radon spaces). Let be a Borel-measurable function. Given probability measures on and on , Monge's formulation of the optimal transportation problem is to find a transport map that realizes the infimum
where denotes the push forward of by . A map that attains this infimum (i.e. makes it a minimum instead of an infimum) is called an "optimal transport map".
Monge's formulation of the optimal transportation problem can be ill-posed, because sometimes there is no satisfying : this happens, for example, when is a Dirac measure but is not.
We can improve on this by adopting Kantorovich's formulation of the optimal transportation problem, which is to find a probability measure on that attains the infimum
where denotes the collection of all probability measures on with marginals on and on . It can be shown[10] that a minimizer for this problem always exists when the cost function is lower semi-continuous and is a tight collection of measures (which is guaranteed for Radon spaces and ). (Compare this formulation with the definition of the Wasserstein metric on the space of probability measures.) A gradient descent formulation for the solution of the Monge–Kantorovich problem was given by Sigurd Angenent, Steven Haker, and Allen Tannenbaum.[11]
Duality formula
The minimum of the Kantorovich problem is equal to
where the supremum runs over all pairs of bounded and continuous functions and such that
Economic interpretation
The economic interpretation is clearer if signs are flipped. Let stand for the vector of characteristics of a worker, for the vector of characteristics of a firm, and for the economic output generated by worker matched with firm . Setting and , the Monge–Kantorovich problem rewrites: which has dual : where the infimum runs over bounded and continuous function and . If the dual problem has a solution, one can see that: so that interprets as the equilibrium wage of a worker of type , and interprets as the equilibrium profit of a firm of type .[12]
Solution of the problem
Optimal transportation on the real line
For , let denote the collection of probability measures on that have finite -th moment. Let and let , where is a convex function.
- If has no atom, i.e., if the cumulative distribution function of is a continuous function, then is an optimal transport map. It is the unique optimal transport map if is strictly convex.
- We have
The proof of this solution appears in Rachev & Rüschendorf (1998).[13]
Discrete version and linear programming formulation
In the case where the margins and are discrete, let and be the probability masses respectively assigned to and , and let be the probability of an assignment. The objective function in the primal Kantorovich problem is then
and the constraint expresses as
and
In order to input this in a linear programming problem, we need to vectorize the matrix by either stacking its columns or its rows, we call this operation. In the column-major order, the constraints above rewrite as
- and
where is the Kronecker product, is a matrix of size with all entries of ones, and is the identity matrix of size . As a result, setting , the linear programming formulation of the problem is
which can be readily inputted in a large-scale linear programming solver (see chapter 3.4 of Galichon (2016)[12]).
Semi-discrete case
In the semi-discrete case, and is a continuous distribution over , while is a discrete distribution which assigns probability mass to site . In this case, we can see[14] that the primal and dual Kantorovich problems respectively boil down to: for the primal, where means that and , and: for the dual, which can be rewritten as: which is a finite-dimensional convex optimization problem that can be solved by standard techniques, such as gradient descent.
In the case when , one can show that the set of assigned to a particular site is a convex polyhedron. The resulting configuration is called a power diagram.[15]
Quadratic normal case
Assume the particular case , , and where is invertible. One then has
The proof of this solution appears in Galichon (2016).[12]
Separable Hilbert spaces
Let be a separable Hilbert space. Let denote the collection of probability measures on that have finite -th moment; let denote those elements that are Gaussian regular: if is any strictly positive Gaussian measure on and , then also.
Let , , for . Then the Kantorovich problem has a unique solution , and this solution is induced by an optimal transport map: i.e., there exists a Borel map such that
Moreover, if has bounded support, then
for -almost all for some locally Lipschitz, c-concave and maximal Kantorovich potential . (Here denotes the Gateaux derivative of .)
Entropic regularization
Consider a variant of the discrete problem above, where we have added an entropic regularization term to the objective function of the primal problem
One can show that the dual regularized problem is
where, compared with the unregularized version, the "hard" constraint in the former dual () has been replaced by a "soft" penalization of that constraint (the sum of the terms ). The optimality conditions in the dual problem can be expressed as
Denoting as the matrix of term , solving the dual is therefore equivalent to looking for two diagonal positive matrices and of respective sizes and , such that and . The existence of such matrices generalizes Sinkhorn's theorem and the matrices can be computed using the Sinkhorn–Knopp algorithm,[16] which simply consists of iteratively looking for to solve Equation 5.1, and to solve Equation 5.2. Sinkhorn–Knopp's algorithm is therefore a coordinate descent algorithm on the dual regularized problem.
Applications
The Monge–Kantorovich optimal transport has found applications in wide range in different fields. Among them are:
- Image registration and warping[17]
- Reflector design[18]
- Retrieving information from shadowgraphy and proton radiography[19]
- Seismic tomography and reflection seismology[20]
- The broad class of economic modelling that involves gross substitutes property (among others, models of matching and discrete choice).
See also
- Wasserstein metric
- Transport function
- Hungarian algorithm
- Transportation planning
- Earth mover's distance
- Monge–Ampère equation
References
- ↑ G. Monge. Mémoire sur la théorie des déblais et des remblais. Histoire de l’Académie Royale des Sciences de Paris, avec les Mémoires de Mathématique et de Physique pour la même année, pages 666–704, 1781.
- ↑ Schrijver, Alexander, Combinatorial Optimization, Berlin; New York : Springer, 2003. ISBN 3540443894. Cf. p. 362
- ↑ Ivor Grattan-Guinness, Ivor, Companion encyclopedia of the history and philosophy of the mathematical sciences, Volume 1, JHU Press, 2003. Cf. p.831
- ↑ L. Kantorovich. On the translocation of masses. C.R. (Doklady) Acad. Sci. URSS (N.S.), 37:199–201, 1942.
- ↑ Cédric Villani (2003). Topics in Optimal Transportation. American Mathematical Soc.. p. 66. ISBN 978-0-8218-3312-4.
- ↑ Singiresu S. Rao (2009). Engineering Optimization: Theory and Practice (4th ed.). John Wiley & Sons. pp. 221. ISBN 978-0-470-18352-6.
- ↑ Frank L. Hitchcock (1941) "The distribution of a product from several sources to numerous localities", MIT Journal of Mathematics and Physics 20:224–230 MR0004469.
- ↑ D. R. Fulkerson (1956) Hitchcock Transportation Problem, RAND corporation.
- ↑ L. R. Ford Jr. & D. R. Fulkerson (1962) § 3.1 in Flows in Networks, page 95, Princeton University Press
- ↑ L. Ambrosio, N. Gigli & G. Savaré. Gradient Flows in Metric Spaces and in the Space of Probability Measures. Lectures in Mathematics ETH Zürich, Birkhäuser Verlag, Basel. (2005)
- ↑ Angenent, S.; Haker, S.; Tannenbaum, A. (2003). "Minimizing flows for the Monge–Kantorovich problem". SIAM J. Math. Anal. 35 (1): 61–97. doi:10.1137/S0036141002410927.
- ↑ 12.0 12.1 12.2 Galichon, Alfred. Optimal Transport Methods in Economics. Princeton University Press, 2016.
- ↑ Rachev, Svetlozar T., and Ludger Rüschendorf. Mass Transportation Problems: Volume I: Theory. Vol. 1. Springer, 1998.
- ↑ Santambrogio, Filippo. Optimal Transport for Applied Mathematicians. Birkhäuser Basel, 2016. In particular chapter 6, section 4.2.
- ↑ "Power diagrams: properties, algorithms and applications", SIAM Journal on Computing 16 (1): 78–96, 1987, doi:10.1137/0216006.
- ↑ Peyré, Gabriel and Marco Cuturi (2019), "Computational Optimal Transport: With Applications to Data Science", Foundations and Trends in Machine Learning: Vol. 11: No. 5-6, pp 355–607. DOI: 10.1561/2200000073.
- ↑ Haker, Steven; Zhu, Lei; Tannenbaum, Allen; Angenent, Sigurd (1 December 2004). "Optimal Mass Transport for Registration and Warping" (in en). International Journal of Computer Vision 60 (3): 225–240. doi:10.1023/B:VISI.0000036836.66311.97. ISSN 0920-5691.
- ↑ Glimm, T.; Oliker, V. (1 September 2003). "Optical Design of Single Reflector Systems and the Monge–Kantorovich Mass Transfer Problem" (in en). Journal of Mathematical Sciences 117 (3): 4096–4108. doi:10.1023/A:1024856201493. ISSN 1072-3374.
- ↑ Kasim, Muhammad Firmansyah; Ceurvorst, Luke; Ratan, Naren; Sadler, James; Chen, Nicholas; Sävert, Alexander; Trines, Raoul; Bingham, Robert et al. (16 February 2017). "Quantitative shadowgraphy and proton radiography for large intensity modulations". Physical Review E 95 (2): 023306. doi:10.1103/PhysRevE.95.023306. PMID 28297858. Bibcode: 2017PhRvE..95b3306K.
- ↑ Metivier, Ludovic (24 February 2016). "Measuring the misfit between seismograms using an optimal transport distance: application to full waveform inversion". Geophysical Journal International 205 (1): 345–377. doi:10.1093/gji/ggw014. Bibcode: 2016GeoJI.205..345M. https://academic.oup.com/gji/article-abstract/205/1/345/2594839.
Further reading
- Brualdi, Richard A. (2006). Combinatorial matrix classes. Encyclopedia of Mathematics and Its Applications. 108. Cambridge: Cambridge University Press. ISBN 978-0-521-86565-4. https://archive.org/details/combinatorialmat0000brua.
 |  |
 EncycloReader
is supported by the
EncycloReader
is supported by the