Ellsberg-Paradoxon
 From Wikipedia (De) - Reading time: 13 min
From Wikipedia (De) - Reading time: 13 min

Bei dem Ellsberg-Paradoxon handelt es sich um ein Paradoxon aus der Entscheidungstheorie, bei dem Entscheidungen die Postulate der (subjektiven) Erwartungsnutzen-Theorie (subjective expected utility – SEU) verletzen, die in weiten Teilen der Ökonomie nicht nur als normative Basis für Entscheidungen gesehen wird, sondern auch als Grundlage von deskriptiven Modellen dient.[1][2][3] Ein solches Wahlverhalten lässt sich generell nicht als eine zugrunde liegende einzelne Wahrscheinlichkeitsverteilung auffassen[4] und ist somit insbesondere nicht durch Risikoeinstellungen (Risikoaversion, -neutralität oder -affinität) erklärbar. Daniel Ellsberg trifft deswegen die zusätzliche Unterscheidung zwischen Risiko und Ungewissheit (im Original ambiguity).[5] Ein wichtiges Resultat des Experiments ist, dass Menschen häufig ein Risiko – dessen Wahrscheinlichkeitsverteilung bekannt ist – einer Situation von Ungewissheit vorziehen, selbst wenn die wahrgenommenen Wahrscheinlichkeiten konstant gehalten werden.[6]
Historischer Hintergrund
[Bearbeiten | Quelltext bearbeiten]Sowohl John Maynard Keynes als auch Frank Knight setzen sich bereits in den 1920er-Jahren mit dem Konzept von Ungewissheit auseinander.
So schreibt F.H. Knight:
„Unsicherheit muss als etwas radikal anderes als die vertraute Bedeutung von Risiko aufgefasst werden, von der es nie ordentlich getrennt wurde […] Die entscheidende Tatsache ist: Risiko meint in manchen Fällen eine messbare Quantität, während es in anderen Fällen etwas bezeichnet, das einen völlig anderen Charakter hat; und es gibt weitreichende und entscheidende Unterschiede bzgl. des Verhaltens von Phänomenen je nachdem welche dieser [Bedeutungen] tatsächlich vorliegt.[…] Es scheint, dass messbare Unsicherheit - „risk proper“ genannt - sich von nicht-messbarer [Unsicherheit] in einem solchen Ausmaß unterscheidet, dass es sich [bei Erstem] im Endeffekt überhaupt nicht um eine Unsicherheit handelt.“
Außerdem wird häufig angeführt, dass die Konzepte, die Keynes 1921 in seiner A Treatise on Probability entwickelt, sehr eng mit der Kritik am SEU Modell, die Ellsberg formuliert, verwandt sind. Unter anderem führt er dort ein Konzept von Ungewissheit ein, die er als non-comparable probabilities bezeichnet.[8]
Abgrenzung zwischen Risiko, Unsicherheit und Ungewissheit
[Bearbeiten | Quelltext bearbeiten]
Bei (1) und (2) Sind jeweils mögliche Ergebnisse und Wahrscheinlichkeiten bekannt, während bei (4) nur die möglichen Ergebnisse aber keine Wahrscheinlichkeiten bekannt sind. Bei (3) enthält die Urne ein extrem folgenschweres Ergebnis, das entweder extrem gut ('Diamant') oder extrem schlecht sein kann ('Bombe'). Bei (5) sind weder mögliche Realisationen noch Wahrscheinlichkeiten bekannt. Wobei (4) und (5) Entscheidungen unter Ambiguität darstellen.[9]
In der realen Welt müssen Menschen Entscheidungen in ganz unterschiedlichen Situationen treffen.
Schon Knight unterscheidet zwischen
(i) a priori Wahrscheinlichkeiten, die in Zufallsspielen logisch hergeleitet werden können;
(ii) Statistischen Wahrscheinlichkeiten, die aus empirischen Daten gewonnen werden; und
(iii) Vorhersagen in Situationen, in denen es keinerlei Basis für irgendeine Art der Klassifizierung gibt.
Daran angelehnt können verschiedene Szenarien von Sicherheit/Risiko/Ungewissheit(Ambiguität) unterschieden werden.[9]
Das Ellsberg-Experiment beinhaltet dabei sowohl Risiko (die Urne bzw. Farben deren Verteilung bekannt ist) als auch Ungewissheit/Ambiguität („Knightian uncertainty“ – die Urne bzw. die Farben deren Verteilung nicht bekannt ist).
Subjektive Erwartungsnutzen-Theorie
[Bearbeiten | Quelltext bearbeiten]Häufig erscheint es plausibel, dass aus Wetten von Agenten bzgl. verschiedener Lotterien direkt deren (subjektive) Wahrscheinlichkeitsverteilungen ableitbar sind, dabei unterstellt man allerdings automatisch, dass diese rational im Rahmen einer (subjektive) Erwartungsnutzen-Theorie (subjective expected utility – SEU) agieren. Das bedeutet insbesondere, man unterstellt, dass zwischen Ereignissen zumindest eine „qualitative Wahrscheinlichkeitsbeziehung“ vorliegt.
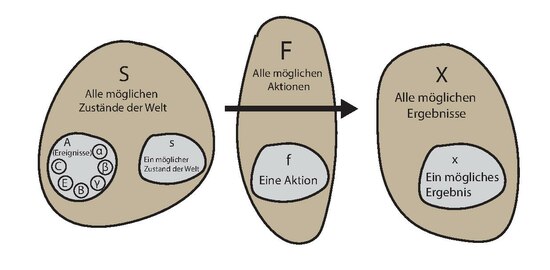
Damit eine Beziehung ![]() zwischen Ereignissen die Eigenschaften einer „qualitativen Wahrscheinlichkeitsbeziehung“ hat, müssen insbesondere folgende Bedingungen erfüllt sein:[10]
( und bezeichnen die Komplemente zu α und β)
zwischen Ereignissen die Eigenschaften einer „qualitativen Wahrscheinlichkeitsbeziehung“ hat, müssen insbesondere folgende Bedingungen erfüllt sein:[10]
( und bezeichnen die Komplemente zu α und β)


 ordnet alle Ereignisse; für zwei Ereignisse α und β gilt: Entweder ist α „nicht weniger wahrscheinlich“ als β oder β ist „nicht weniger wahrscheinlich als“ α; und falls α ≥ β und β ≥ γ ⇒ α ≥ γ
ordnet alle Ereignisse; für zwei Ereignisse α und β gilt: Entweder ist α „nicht weniger wahrscheinlich“ als β oder β ist „nicht weniger wahrscheinlich als“ α; und falls α ≥ β und β ≥ γ ⇒ α ≥ γ- Wenn α wahrscheinlicher als β ist ⇒ ist weniger wahrscheinlich als ; falls α gleich wahrscheinlich wie ist und β gleich wahrscheinlich wie ist ⇒ α ist gleich wahrscheinlich wie β
- Schließen sich α und γ gegenseitig aus und β und γ ebenfalls (α ∩ γ = β ∩ γ = 0), und gilt gleichzeitig α ist wahrscheinlicher als β ⇒ Die Vereinigung (α ∪ γ) ist wahrscheinlicher als (β ∪ γ)
Um nun von den Entscheidungen der Agenten (Aktionen) auf eine zugrunde liegende „qualitative Wahrscheinlichkeitsbeziehung“ bzgl. der Ereignisse schließen zu können, muss die Beziehung ≿ zwischen den Aktionen einigen axiomatischen Beschränkungen unterliegen. Ein solches System sind die Savage Postulate, wobei die wichtigsten Folgende sind:[11][12]
- P1 (Ordering): Die Beziehung ≿ ist vollständig, reflexiv und transitiv.
- P2 (Sure-Thing Principle): Die Präferenzordnung zwischen zwei Aktionen f und f*, hängt nur von Werten von f und f* ab, in denen sie sich unterscheiden. Das heißt für zwei Aktionen f und f*, die sich nur bei einem speziellen Ereignis E unterscheiden und ansonsten gleich sind, ist für den Vergleich irrelevant, welche Werte diese außerhalb von E annehmen.
![{\displaystyle \left[{\begin{array}{ll}f^{*}(s)&{\mbox{if }}s\in E\\g(s)&{\mbox{if }}s\notin E\end{array}}\right]\succsim \left[{\begin{array}{ll}f(s)&{\mbox{if }}s\in E\\g(s)&{\mbox{if }}s\notin E\end{array}}\right]\Rightarrow \left[{\begin{array}{ll}f^{*}(s)&{\mbox{if }}s\in E\\h(s)&{\mbox{if }}s\notin E\end{array}}\right]\succsim \left[{\begin{array}{ll}f(s)&{\mbox{if }}s\in E\\h(s)&{\mbox{if }}s\notin E\end{array}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0b2792e4c87527cca6fc8ca3290c05465c0f534b)
- P3 (Eventwise Monotonicity): Gegeben sei eine Aktion, die im Falle von (dem nichtleeren) Ereignis E immer das Ergebnis x erzielt. Wenn diese Aktion nun so geändert wird, dass sie im Falle von E immer das Ergebnis y erzielt, dann sollte die Präferenz zwischen den beiden Aktionen genau der Präferenz zwischen den Ergebnissen x und y entsprechen (oder genauer gesagt: Der Ordnung der konstanten Funktionen, die x bzw. y erzielen).
![{\displaystyle \left[{\begin{array}{ll}x&{\mbox{if }}s\in E\\g(s)&{\mbox{if }}s\notin E\end{array}}\right]\succsim \left[{\begin{array}{ll}y&{\mbox{if }}s\in E\\g(s)&{\mbox{if }}s\notin E\end{array}}\right]\Leftrightarrow x\succsim y}](https://wikimedia.org/api/rest_v1/media/math/render/svg/84461945b593326c0547e0551395dfa541a5bd97)
- P4 (Weak Comparative Probability): P4 dient dazu, eine (qualitative) Rangfolge von Ereignissen zu etablieren. Gegeben die Ergebnisse x*≻x und y*≻y, dann gilt für alle Ereignisse A und B: ( und bezeichnen die Komplemente zu A und B)


![{\displaystyle \left[{\begin{array}{ll}x^{*}&{\mbox{if }}A\\x&{\mbox{if }}{\overline {A}}\end{array}}\right]\succsim \left[{\begin{array}{ll}x^{*}&{\mbox{if }}B\\x&{\mbox{if }}{\overline {B}}\end{array}}\right]\Leftrightarrow \left[{\begin{array}{ll}y^{*}&{\mbox{if }}A\\y&{\mbox{if }}{\overline {A}}\end{array}}\right]\succsim \left[{\begin{array}{ll}y^{*}&{\mbox{if }}B\\y&{\mbox{if }}{\overline {B}}\end{array}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b5d4688730c63b27213174b34b63c13777fee75)
Ellsberg-Experiment
[Bearbeiten | Quelltext bearbeiten]Das Ellsberg-Paradoxon geht auf die von Daniel Ellsberg 1961 veröffentlichte Arbeit „Risk, ambiguity and the Savage axioms“ zurück. Dort stellt er zwei Versionen eines Urnenexperiments vor, die beide zur Schlussfolgerung kommen, dass Menschen in den meisten Situationen Ungewissheits-Aversion zeigen.[5]
2-Farben-Version
[Bearbeiten | Quelltext bearbeiten]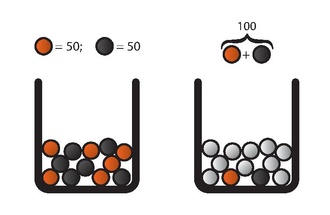
Links: Urne1, Rechts Urne2
Der Aufbau ist folgender: Es gibt zwei Urnen, die jeweils genau 100 Kugeln enthalten. In Urne1 befinden sich – vom Agenten nachprüfbar – genau 50 rote und 50 schwarze Kugeln. In Urne2 befinden sich ebenfalls 100 Kugeln, allerdings ist die Verteilung zwischen Schwarz und Rot unbekannt; sie kann also jede beliebige Kombination enthalten, von (100 Rot2 & 0 Schwarz2) bis (0 Rot2 & 100 Schwarz2) inklusive aller dazwischenliegenden Verteilungen. Die folgenden Aktionen werden dem Agenten (nacheinander) angeboten:
- Wette auf Rot1 oder Schwarz1 oder indifferent?
- Wette auf Rot2 oder Schwarz2 oder indifferent?
- Wette auf Rot1 oder Rot2 oder indifferent?
- Wette auf Schwarz1 oder Schwarz2 oder indifferent?
Wobei Rot1 einer (zufällig gezogenen) roten Kugel aus Urne1 entspricht und Schwarz2 einer (zufällig gezogenen) schwarzen Kugel aus Urne2.
Das typische Antwortmuster, das sich dabei ergibt lautet (Set1): Im Fall 1 und 2 Indifferenz. Im Fall 3: Rot1 wird gegenüber Rot2 bevorzugt und im Fall 4: Schwarz1 wird gegenüber Schwarz2 bevorzugt.
Es gibt auch das (wesentlich seltenere) Muster, bei dem Fall 3 und Fall 4 jeweils genau umgekehrt als in Set1 beantwortet werden (Set2). Im Fall 3: Rot2 wird gegenüber Rot1 bevorzugt und im Fall 4: Schwarz2 wird gegenüber Schwarz1 bevorzugt.
Darüber hinaus gibt es ein drittes Muster, bei dem Indifferenz über alle Antwortmöglichkeiten besteht (Set3). Weitere Antwortmuster sind möglich, allerdings noch seltener. Letzteres (Set3) ist auch das Einzige, – gegeben Fall 1 & 2 Indifferenz – das konsistent mit den Savage Axiomen bzw. SEU allgemein ist. Sowohl Set1 als auch Set2 verletzen Axiome, die notwendig sind, um aus den Antworten eine SEU abzuleiten, wobei Set1 den (typischen) Fall von Ungewissheitsaversion und Set2 den (wesentlich selteneren) Fall von Ungewissheitsaffinität darstellt. Um den Widerspruch zu verstehen, nehmen wir an, dass wir uns in Set2 befinden: Ein Beobachter, der die Savage-Axiome zugrunde legt, würde aus der Wahl in Fall 3: Rot1 ≺ Rot2 schließen, dass wir Rot2 als wahrscheinlicher als Rot1 erachten. Gleichzeitig bevorzugen wir aber auch Schwarz2 gegenüber Schwarz1, woraus folgen würde, dass wir Schwarz2 als wahrscheinlicher als Schwarz1 ansehen. Da aber in unserem Experiment Schwarz1 genau (Komplement Rot1) und Schwarz2 genau (Komplement Rot2) entspricht, würde das bedeuten, dass wir Rot2 für wahrscheinlicher als Rot1 und gleichzeitig als wahrscheinlicher als erachten. Dies ist aber ein offensichtlicher Widerspruch.[13]


3-Farben-Version
[Bearbeiten | Quelltext bearbeiten]Eine andere Version des Ellsberg-Experiments ist folgende:[14]
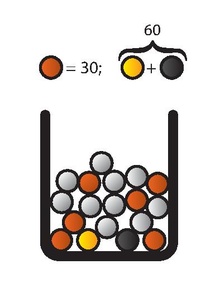
In einer Urne befinden sich 30 rote und 60 Kugeln, die schwarz und gelb sind, allerdings ist die Verteilung zwischen Schwarz und Gelb unbekannt. Es wird eine Kugel zufällig aus der Urne gezogen. Nun muss wieder zwischen den folgenden Aktionen paarweise gewählt werden: Zuerst
| 30 | 60 | ||
|---|---|---|---|
| Rot | Schwarz | Gelb | |
| Aktion I | 100 € | 0 € | 0 € |
| Aktion II | 0 € | 100 € | 0 € |
Der Agent hat die Wahl zwischen Aktion I (Wette auf Rot), oder Aktion II (Wette auf Schwarz).
Und anschließend unter denselben Bedingungen:
| 30 | 60 | ||
|---|---|---|---|
| Rot | Schwarz | Gelb | |
| Aktion III | 100 € | 0 € | 100 € |
| Aktion IV | 0 € | 100 € | 100 € |
Der Agent kann zwischen Aktion III (Wette auf Rot oder Gelb) oder Aktion IV (Wette auf Schwarz oder Gelb) wählen
Auch hier ergibt sich als typisches Antwortmuster (Set1):
Aktion I wird Aktion II bevorzugt und
Aktion IV wird Aktion III bevorzugt
Wesentlich seltener gibt es das gegenteilige Muster (Set2):
Aktion II wird Aktion I bevorzugt und
Aktion III wird Aktion IV bevorzugt.
Beide Sets stellen eine direkte Verletzung des Sure-thing Principle dar, nach dem die Ordnung des ersten Paares (Aktion I und II) ebenfalls im zweiten Paar gewahrt bleiben müsste (Aktion III und IV), da Aktion III nichts anderes als Aktion I und Aktion IV nichts anderes als Aktion II ist. Der einzige Unterschied ist, dass die letzte Spalte jeweils um einen konstanten Betrag erhöht wurde. Damit gibt es auch hier wieder keine Kombination von Gelb und Schwarz, die mit dieser Wahl im Rahmen einer SEU korrespondieren würde.
Probabilistic Sophistication
[Bearbeiten | Quelltext bearbeiten]Eine allgemeinere Version des SEU Modells führen Mark J. Machina und David Schmeidler ein, in der Präferenzen nicht notwendigerweise mit der Erwartungsnutzen-Hypothese konform sein müssen, sich allerdings weiterhin mit einer Wahrscheinlichkeitsverteilung beschreiben lassen. Der Hauptunterschied liegt darin, dass Erwartungsnutzenfunktionen (subjektive) Wahrscheinlichkeiten linear kombinieren, während „probabilistic sophistication“ dies nicht fordert. „Probabilistic sophistication“ ist somit eine schwächere Forderung als diejenigen, die benötigt werden, um eine SEU zu konstruieren: Verletzungen des Sure-Thing Principle oder der Erwartungsnutzentheorie im Allgemeinen implizieren nicht generell eine Verletzung von „probabilistic sophistication“.[15]
Doch auch diese schwächeren Forderungen werden im Ellsberg-Paradox verletzt. Die dort getroffenen Entscheidungen lassen keinen Schluss auf eine zugrunde liegende Wahrscheinlichkeitsverteilung (linear oder anderweitig) zu.[16]
Normative und deskriptive Perspektive
[Bearbeiten | Quelltext bearbeiten]In der Ökonomie bilden SEU-Annahmen häufig die Grundlage von deskriptiven rational-agent-Modellen.[1][2][3] Für eine solche Auslegung stellt das Ellsberg-Paradoxon einen direkten Widerspruch dar und ist ohne Änderung der Modellbasis oder expliziter Beschränkung des Anwendungsbereiches nicht integrierbar. Die eventuell schwächere Behauptung, dass den Savage-Axiomen zumindest eine normative Rolle zukomme, ist leichter zu verteidigen, wobei sich auch hier ein Problem ergibt, da Individuen in bestimmten Situationen selbst nach Reflexion die Axiome absichtlich verletzen, ihre Normativität somit nicht anerkennen.[17] Ellsberg argumentiert, dass bei diesem Verhalten zumindest drei Eigenschaften, die üblicherweise mit irrationalen Verhalten assoziiert sind, nicht vorzufinden sind, nämlich:
- a) Dass dieses Verhalten unvorhersagbar ist (sich also keine formalen Entscheidungsregeln finden lassen).
- b) Dass es Intransitivität aufweist.
- c) Dass es Nutzen verwirft, indem es z. B. strikt dominierte Strategien wählt.[18]
Der letzte Punkt (c) ist allerdings fragwürdig: Solange wir uns in der Situation des Ausgangsbeispiels der Drei-Farben-Version bewegen und als Benchmark eine Wahl gemäß der Laplace-Regel (1/3;1/3;1/3) anlegen, ist die Wahl von Wette I und IV nicht tatsächlich mit Nachteilen verbunden, da jede andere Wahl die gleiche erwartete Auszahlung generiert. Wenn man nun allerdings ein Premium für die „gefühlt sichere Wahl“ zahlt (also ein Premium für Wette I gegenüber Wette II und gleichzeitig ein Premium für Wette IV gegenüber Wette III), ist dieses von dem erwarteten Gewinn zu subtrahieren, und damit verliert diese Strategie gegenüber der Laplace-Referenzstrategie. bzw. jeder anderen SEU Strategie, die keine solchen Prämien zahlt, da es nicht möglich ist, dass es mehr rote als schwarze Kugeln gibt, aber gleichzeitig mehr schwarze als rote Kugeln (Es handelt sich schließlich um dieselbe Urne). Dies gilt unabhängig von der zugrunde liegenden Nutzenfunktion und insbesondere unabhängig von der Risikoaversion.
Kritik an der normativen Gültigkeit einer solchen Wahl kommt unter anderem auch von Howard Raiffa:[19]
Er schlägt als Gedankenexperiment eine Randomisierung vor:
Angenommen ein Individuum hat die (typische) Präferenzordnung I≻II und IV≻III.
Nun werden ihm zwei Wetten angeboten:
Option A: Eine faire Münze wird geworfen und im Falle von Kopf wird Wette I gespielt und im Falle von Zahl Wette IV
Option B: Eine faire Münze wird geworfen und im Falle von Kopf wird Wette II gespielt und im Falle von Zahl Wette III
| Kopf | Zahl | |
|---|---|---|
| Option A | Aktion I | Aktion IV |
| Option B | Aktion II | Aktion III |
Aufgrund von strikter Dominanz sollte ein Individuum, das die obigen Präferenzen hat, nun Option A gegenüber Option B ebenfalls strikt bevorzugen. Wenn wir nun allerdings die Situation – aus der Position, in der eine bestimmte Farbe gezogen wurde – analysieren, stellt sich das folgendermaßen dar:

Aus dieser Perspektive scheinen Option A und Option B objektiv identisch zu sein und somit eine Prämie für A zu zahlen irrational.[19] Bei diesem Aufbau ist gleichzeitig sichergestellt, dass Verzerrungen durch das feindliche Umwelt Szenario nicht auftreten können, da der Experimentator nicht wissen kann ob Kopf oder Zahl fallen wird und damit die Urnen auch nicht manipulieren kann.
Erklärungen
[Bearbeiten | Quelltext bearbeiten]Feindliche Umwelt
[Bearbeiten | Quelltext bearbeiten]Falls nicht klar ist, dass sich alle Fragen auf dieselbe Urne beziehen, könnte das Angebot der Wetten als Signal in einem Spiel mit einer „feindlichen Instanz“ aufgefasst werden, deren Ziel es ist, den Gewinn des Spielers zu minimieren, da z. B. die Ausführung des Experiments für sie dann „günstiger“ wäre. In einem solchen Fall könnte der Spieler annehmen, dass die ungewissen Optionen jeweils zu seinem Nachteil ausfallen: Bei der Wahl zwischen Rot und Schwarz würde er annehmen, dass vermutlich weniger schwarze als rote Kugeln vorhanden sind, während er in der Situation, dass er zwischen (Rot und Gelb) vs. (Schwarz und Gelb) wählen muss, davon ausgeht, dass weniger gelbe als rote Kugeln vorhanden sind (3-Farben-Version).[20]
Info-Gap-Entscheidungstheorie
[Bearbeiten | Quelltext bearbeiten]Diese Herangehensweise nimmt an, dass der Agent keinen Erwartungsnutzen maximieren kann, da er keine genauen Wahrscheinlichkeiten kennt. Anstelle von subjektiven Wahrscheinlichkeiten formuliert er nun intern ein Info-Gap-Modell[21] für den Teil, für den er keine Wahrscheinlichkeiten kennt und so versucht, die Robustheit der Entscheidung gegenüber der Ungewissheit in diesem Teil zu maximieren.[20]
Comparative Ignorance Hypothesis
[Bearbeiten | Quelltext bearbeiten]Craig R. Fox und Amos Tversky argumentieren, dass sich die Ambiguitätsaversion nur aus dem Vergleich zwischen Optionen mit unterschiedlichem Grad von Ambiguität ergebe. Insbesondere bedeutet das, dass eine solche Aversion in Abwesenheit von vergleichbaren Optionen (also bei einer isolierten Wahl), verschwindet bzw. stark zurückgeht.[22]
Ökonomische Entscheidungsmodelle unter Ambiguität
[Bearbeiten | Quelltext bearbeiten]Seit seiner Popularisierung durch D. Ellsberg 1961 hat das Ellsberg-Paradoxon, beziehungsweise das gesamte Gebiet der Entscheidungstheorie unter Ungewissheit/Ambiguität, einen erheblichen Zuwachs an Forschung, sowie deutliche theoretische und experimentelle Fortschritte erlebt. Dabei hat sich eine Vielzahl von Modellen ergeben, die auf unterschiedliche Weise Ungewissheit modellieren und erklären. Diese Modelle sind generell leistungsfähiger als ein reines SEU Modell, da sie dieses als Spezialfall bereits enthalten.[23] Eine Übersicht der Entwicklung geben (Etner et al., 2012)[23] sowie (Camerer & Weber, 1992)[24]. Als wichtigste Modelle zu nennen sind die von David Schmeidler 1989 entwickelte Choquet expected utility[25], sowie die von Itzhak Gilboa & Schmeidler 1989 entwickelte Maxmin expected utility[26]. Mit der dadurch – gegenüber einer SEU-Modellierung – gewonnenen erhöhten deskriptiven Validität, geht jedoch gleichzeitig eine gesteigerte Komplexität durch die Erhöhung der Parameteranzahl einher. Das äußert sich zum Beispiel darin, dass in einer dynamischen Situation die zusätzliche Unterscheidung getroffen werden muss, zwischen Agenten, die sich nicht konsequentialistisch verhalten und jenen, die sich nicht dynamisch konsistent verhalten.[27]
Siehe auch
[Bearbeiten | Quelltext bearbeiten]Literatur
[Bearbeiten | Quelltext bearbeiten]- D. Ellsberg: Risk, ambiguity, and decision. Taylor & Francis, 2001.
- J. Etner et al.: Decision Theory under Ambiguity In: Journal of Economic Surveys. Vol. 26, Nr. 2, 2012, S. 234–270. doi: 10.1111/j.1467-6419.2010.00641.x
- C. Camerer und M. Weber: Recent Developments in Modeling Preferences: Uncertainty and Ambiguity. In: Journal of Risk and Uncertainty. Nr. 5, 1992, S. 325–370. doi:10.1007/BF00122575
- Bruno de Finetti: Foresight: its logical laws, its subjective sources (1937), in H. E. Kyburg und H. E. Smokler (Hg.), Studies in Subjective Probability, New York: Wiley, 1964, 93–159.
Weblinks
[Bearbeiten | Quelltext bearbeiten]Einzelnachweise
[Bearbeiten | Quelltext bearbeiten]- ↑ a b Vgl. Homo oeconomicus
- ↑ a b Economist - IRRATIONALITY Rethinking thinking Dec 16th 1999
- ↑ a b Economist, Behaviourists at the gates; May 8th 2003
- ↑ J. Eichberger et al.: Ambiguity and social interaction. In: Oxford Economic Papers. Nr. 61, 2009, S. 355–379.
- ↑ a b D. Ellsberg: Risk, ambiguity and the Savage axioms In: Quarterly Journal of Economics Vol. 75, Nr. 4, 1961, S. 643–669.
- ↑ C. Camerer und M. Weber: Recent Developments in Modeling Preferences: Uncertainty and Ambiguity. In: Journal of Risk and Uncertainty. Nr. 5, 1992, S. 325,360.
- ↑ F. H. Knight, Risk, Uncertainty, and Profit., Boston, MA: Hart, Schaffner & Marx; Houghton Mifflin Company, 1921
- ↑ A. Feduzi: On the relationship between Keynes’s conception of evidential weight and the Ellsberg paradox. In: Journal of Economic Psychology. Nr. 28, 2007, S. 545–565.
- ↑ a b B. Meder et al.: Decision making in uncertain times: what can cognitive and decision sciences say about or learn from economic crises? In: Trends in Cognitive Sciences. Vol. 17, Nr. 6, 2013, S. 257–260.
- ↑ D. Ellsberg: Risk, ambiguity and the Savage axioms In: Quarterly Journal of Economics Vol. 75, Nr. 4, 1961, S. 648.
- ↑ M. J. Machina und D. Schmeidler: A More Robust Definition of Subjective Probability. In: Econometrica. Vol. 60, Nr. 4, 1992, S. 749 f.
- ↑ I. Gilboa et al.: Theory of Decision under Uncertainty. Cambridge: Cambridge university press., 2009, S. 97 ff.
- ↑ D. Ellsberg: Risk, ambiguity and the Savage axioms In: Quarterly Journal of Economics Vol. 75, Nr. 4, 1961, S. 650 ff.
- ↑ D. Ellsberg: Risk, ambiguity and the Savage axioms In: Quarterly Journal of Economics Vol. 75, Nr. 4, 1961, S. 654 f.
- ↑ M. J. Machina und D. Schmeidler: A More Robust Definition of Subjective Probability. In: Econometrica. Vol. 60, Nr. 4, 1992, S. 753 f.
- ↑ J. Etner et al.: Decision Theory under Ambiguity In: Journal of Economic Surveys. Vol. 26, Nr. 2, 2012, S. 253. doi: 10.1111/j.1467-6419.2010.00641.x
- ↑ D. Ellsberg: Risk, ambiguity and the Savage axioms In: Quarterly Journal of Economics Vol. 75, Nr. 4, 1961, S. 656.
- ↑ D. Ellsberg: Risk, ambiguity and the Savage axioms In: Quarterly Journal of Economics Vol. 75, Nr. 4, 1961, S. 663.
- ↑ a b H. Raiffa: Risk, Ambiguity, and the Savage Axioms: Comment. In: The Quarterly Journal of Economics. Vol. 75, Nr. 4, 1961, S. 690–694.
- ↑ a b R. Lima Filho: Rationality Intertwined: Classical vs Institutional View. In: SSRN 2389751. 2009, S. 5–6.
- ↑ Y. Ben-Haim: Info-Gap Decision Theory. GB, Academic Press, 2006
- ↑ C.R. Fox & A. Tversky: Ambiguity aversion and comparative ignorance. In: The quarterly journal of economics. 1995, S. 585–603.
- ↑ a b J. Etner et al.: Decision Theory under Ambiguity In: Journal of Economic Surveys. Vol. 26, Nr. 2, 2012, S. 234–270. doi: 10.1111/j.1467-6419.2010.00641.x
- ↑ C. Camerer und M. Weber: Recent Developments in Modeling Preferences: Uncertainty and Ambiguity. In: Journal of Risk and Uncertainty. Nr. 5, 1992, S. 325–370. doi:10.1007/BF00122575
- ↑ D. Schmeidler: Subjective probability and expected utility without additivity. In: Econometrica: Journal of the Econometric Society. 1989, S. 571–587. doi:10.2307/1911053
- ↑ I. Gilboa & D. Schmeidler: Maxmin expected utility with non-unique prior. In: Journal of mathematical economics. Vol. 18, Nr. 2, 1989, S. 141–153. doi:10.1016/0304-4068(89)90018-9
- ↑ A. Dominiak, P. Dürsch & J.P. Lefort: A dynamic Ellsberg urn experiment. In: Games and Economic Behavior. Vol. 75 Nr. 2, 2012, S. 625–638. doi:10.1016/j.geb.2012.01.002
 EncycloReader
is supported by the
EncycloReader
is supported by the